Metastable Failures in Distributed Systems
Recently, I started a new good and healthy habit, which is read papers. I got impressed how it is good, and how important that is the academia is discussing and contributing for current affairs. This is my first comment, thought, compilation of content about the paper ”Metastable Failures in Distributed Systems” written by Nathan Bronson (Rockset, inc), Aleksey Charapko (University of New Hampshire), Adutalib Aghayev (The Pennsylvania State University) and Timothy Zhu (The Pennsylvania State University).
I was in a critical incident when a co-worker figured out this paper, and I read “Metastable Failures” and I thought, “What the fuc*** is that ? Then, I started to understand it better; probably I will write another version about this complex subject.
Metastable failures are a failure patterns in distributed systems. They are an emergent behavior rather than a logic bug, one cannot write a unit or integration test to trigger them; they naturally arise from optimizations and policies that improve behavior, which, in the common case, can have catastrophic effects. A system can run for months or years in a vulnerable state and then get stuck in a mutable state without any increase in load.
Metastable failures manifest in a variety of ways, but the sustaining effect is almost always associated with the exhaustion of some resource.
One behavior that occurs in a system with an uncontrolled source of load is when a trigger causes the system to enter a bad state that persists even when the trigger is removed. In this state, the throughput is unusable low, and there is a sustaining effect, often involving work amplification or decreased overall efficiency.
Phases of Metastable Failure:
- Stable: System starts in a stable state.
- Vulnerable: Once the load rises above a certain threshold (Isn’t an overloaded).
- Metastable: The vulnerable system is healthy, but may fall into an unrecoverable metastable state due to a trigger.
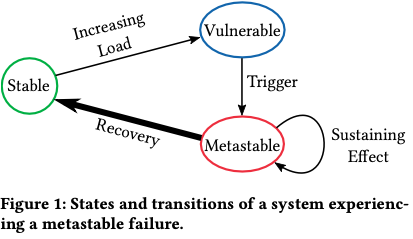
Elastic systems are not immune to metastable failure states, but scaling up to maintain a capacity buffer reduces the vulnerability to most triggers.
The root cause of a metastable failure is the sustaining feedback loop, rather than the trigger. There are many triggers that can lead to the same failure state, so addressing the sustaining effect is much more likely to prevent future outages.
Often find the same root cause manifests failures as latency outliers or a cluster of errors. Even when the feedback loop isn’t strong enough to cause the problem to grow unbounded, it may still cause the trigger to reverberate enough times to stand out
To not get confused about what are NOT cases of Metastable failures, when triggers are removed, such as denial-of-service attacks, limp-lock and live-lock are not included. To stop a metastable failure state, it requires a strong corrective push, such as rebooting the system or dramatically reducing the load.
One important thing to know is that metastable failure will involve identifying the effect as reducing client load. During overload, a good way to weaken or break the feedback loops is to ensure that good put remains high even during overload. This can be done by changing routing and queuing policies during an overload.
- E.g. disable failover and retries
- Set a retry budget
- Switch to LIFO scheduling to allow some requests to meet their deadline, reduce internal queue size, enforce priorities during overload
- Shed load by rejecting a fraction of requests or clientes or event use the circuit breaker pattern to block all requests
Fast error Paths
- One pattern for isolating error handling is to send failures to a dedicated error logging thread via a bounded-size lock-free queue
- If the queue overflows then errors are only reflected in a counter, reducing the per-failure overhead dramatically.
When analyzing metastable failures patterns is that there are often a metrics that is affected by the trigger and that only returns to normal after resolves.
- Latency
- Fraction of requests that timeout
Both of these metrics will spike during the requests surge that follows a network outage, and they won’t recover until after the metastable is resolved.
Follow some characteristics metrics that are observed in production:
- Cache hit rate
- Queuing delay
- Request latency
- Load level
- Working set size
- Page faults
- Swapping
- Timeout rates
- Thread counts
- Lock contention
- Connection counts
- Operation mix
Building robust systems are complex and there are many aspects that need some attention that can appear an open problem such as metastable failures.
It is important to go beyond a simple understand of metastability and learn how to operate in the vulnerable state, therefore, refactoring the design of systems also needs to focus that avoid metastable failures.